refs:
https://www.ans.org/news/article-1294/nuclear-pulse-propulsion-gateway-to-the-stars/
https://ntrs.nasa.gov/api/citations/20000096503/downloads/20000096503.pdf


A global interpreter lock (GIL) is a mutual-exclusion lock held by a programming language interpreter thread to avoid sharing code that is not thread-safe with other threads. In implementations with a GIL, there is always one GIL for each interpreter process.
Applications running on implementations with a GIL can be designed to use separate processes to achieve full parallelism, as each process has its own interpreter and in turn has its own GIL. Otherwise, the GIL can be a significant barrier to parallelism.
Refs
https://www.geeksforgeeks.org/mutex-vs-semaphore/
https://en.wikipedia.org/wiki/CPython
https://en.wikipedia.org/wiki/Global_interpreter_lock
# https://salsa.debian.org/benchmarksgame-team/benchmarksgame/ # contributed by Joerg Baumann
from contextlib import closing from itertools import islice from os import cpu_count from sys import argv, stdout def pixels(y, n, abs): range7 = bytearray(range(7)) pixel_bits = bytearray(128 >> pos for pos in range(8)) c1 = 2. / float(n) c0 = -1.5 + 1j * y * c1 - 1j x = 0 while True: pixel = 0 c = x * c1 + c0 for pixel_bit in pixel_bits: z = c for _ in range7: for _ in range7: z = z * z + c if abs(z) >= 2.: break else: pixel += pixel_bit c += c1 yield pixel x += 8 def compute_row(p): y, n = p result = bytearray(islice(pixels(y, n, abs), (n + 7) // 8)) result[-1] &= 0xff << (8 - n % 8) return y, result def ordered_rows(rows, n): order = [None] * n i = 0 j = n while i < len(order): if j > 0: row = next(rows) order[row[0]] = row j -= 1 if order[i]: yield order[i] order[i] = None i += 1 def compute_rows(n, f): row_jobs = ((y, n) for y in range(n)) if cpu_count() < 2: yield from map(f, row_jobs) else: from multiprocessing import Pool with Pool() as pool: unordered_rows = pool.imap_unordered(f, row_jobs) yield from ordered_rows(unordered_rows, n) def mandelbrot(n): write = stdout.buffer.write with closing(compute_rows(n, compute_row)) as rows: write("P4\n{0} {0}\n".format(n).encode()) for row in rows: write(row[1]) if __name__ == '__main__': mandelbrot(int(argv[1]))
###################################################################################
COMMAND LINE:
/opt/src/Python-3.10.4/bin/python3 -OO mandelbrot.python3-7.py 16000
Refs :
https://en.wikipedia.org/wiki/Mandelbrot_set
https://web.archive.org/web/20010124090400/http://www.bagley.org/~doug/shootout/
https://benchmarksgame-team.pages.debian.net/benchmarksgame/program/mandelbrot-python3-7.html
https://benchmarksgame-team.pages.debian.net/benchmarksgame/description/mandelbrot.html#mandelbrot
1.
AVEDEV( ) calculates the mean of the absolute
deviations from the mean.
2.
AVERAGE( ) returns the arithmetic mean of the
arguments.
3.
COUNT ( ) counts the numbers in the list of
arguments.
4.
COUNTA( ) counts the number of nonblank values.
5.
DEVSQ( ) calculates the sum of squares of
deviations of data points from their 2 sample mean, e.g. ∑(xi − x ) .
6.
GEOMEAN( ) returns the geometric mean of the
arguments.
7.
HARMEAN( ) gives the harmonic mean of the
arguments.
8.
LARGE(array,k) returns the kth largest value in
the array.
9.
MAX( ) gives the maximum value in a list of
arguments.
10.
MEDIAN( ) returns the median of the stated
numbers.
11.
MIN( ) gives the minimum value in a list of
arguments.
12.
MODE( ) returns the mode of the data set.
13.
PERCENTILE(array,k) returns the kth percentile
of numbers in the array.
14.
PERCENTRANK(array,x,) returns the percentage
rank of x among the values in the array.
15.
QUARTILE(array,) returns the minimum,maximum,
median, lower quartile, or upper quartile from the array.
16.
RANK( ) gives the rank (order in a sorted list)
of a number.
17.
STDEV( ) gives the sample standard deviation, s,
of a set of numbers.
18.
STDEVP( ) calculates the standard deviation, σ,
of a set of numbers taken as a complete population.
19.
TRIMMEAN( array) calculates the mean after a
certain percentage of values are removed at the top and the bottom of the set
of numbers.
20.
VAR( ) returns the sample variance, s2, of a set
of numbers.
21.
VARP( ) finds the variance, σ2, of a set of
numbers taken as a complete population.
Mathematical modelling real world application : Research
Mathematical modeling is a process of representing problems from fields beyond
mathematics itself using mathematics. The subsequent mathematical treatment of
this model using theoretical and / or numerical procedures proceeds as above use case.
Modelling techniques are fully based on below topics.
– Linear algebra
– Calculus
– Partial differential equations
– Numerical analysis
– The theory of complex functions
– Functional analysis
Supervisory control and data acquisition (SCADA) is a control system architecture comprising computers, networked data communications and graphical user interfaces for high-level process supervisory management, while also comprising other peripheral devices like programmable logic controllers (PLC) and discrete proportional-integral-derivative controllers to interface with process plant or machinery.SCADA systems are critical as it helps maintain efficiency by collecting and processing real-time data. It is a centralized system that monitors and controls the entire area.

ORCL 10g Installation steps from Stanford source. Go and read if you are interested

https://web.stanford.edu/dept/itss/docs/oracle/10gR2/server.102/b14196/install002.htm#sthref42
A distributed database (DDB) is an integrated collection of databases that is physically distributed across sites in a computer network. A distributed database management system (DDBMS) is the software system that manages a distributed database such that the distribution aspects are transparent to the users. To form a distributed database system (DDBS), the files must be structured, logically interrelated, and physically distributed across multiple sites. In addition, there must be a common interface to access the distributed data.

Pls go to ref read more
https://web.stanford.edu/dept/itss/docs/oracle/10gR2/server.102/b14231/ds_concepts.htm#i1007534
That is very easy :P
On a windows environment.
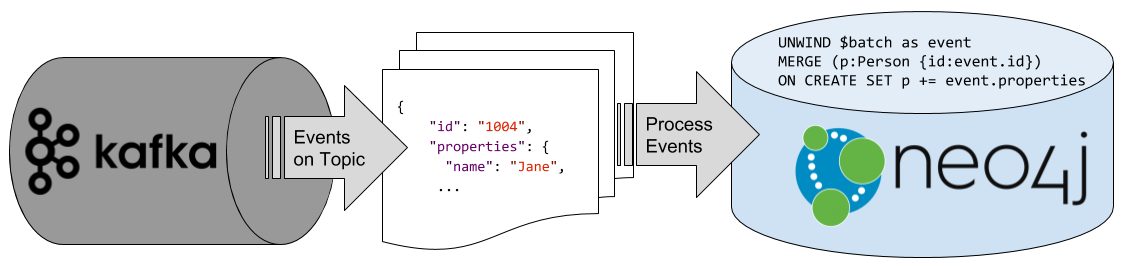
1-> Download neo4j then Next next next .. Done with the DB ..
2-> Download python runtime. 3 or 2 either series would work. then next , next , next ..Done with the Python.
Note : there are many community developed drivers, But for me, below version working perfectly for years :D
Install neo4j library :
pip install neo4j
Sample snippet:
from neo4j import GraphDatabase class HelloWorldExample: def __init__(self, uri, user, password): self.driver = GraphDatabase.driver(uri, auth=(user, password)) def close(self): self.driver.close() def print_greeting(self, message): with self.driver.session() as session: greeting = session.write_transaction(self._create_and_return_greeting, message) print(greeting) @staticmethod def _create_and_return_greeting(tx, message): result = tx.run("CREATE (a:Greeting) " "SET a.message = $message " "RETURN a.message + ', from node ' + id(a)", message=message) return result.single()[0] if __name__ == "__main__": greeter = HelloWorldExample("bolt://localhost:7687", "neo4j", "password") greeter.print_greeting("hello, world") greeter.close()
Now you can play with your Cypher ...


refs: https://www.ans.org/news/article-1294/nuclear-pulse-propulsion-gateway-to-the-stars/ https://ntrs.nasa.gov/api/citations/2000009650...








